There are certain situations in FileMaker development where the current FileMaker found set needs to be recreated. A good example of this is when the Perform Script On Server (PSoS) step is used. Since it runs on the server, the current context (including the found set) is lost and has to be reconstructed.
I used to recreate FileMaker found sets on the server by collecting the primary key values using a custom function and then creating a find request for each value in the list, but this approach does not scale well.
| # Records | Time (seconds) |
|---|---|
| 100 | <1 |
| 1,000 | 2 |
| 10,000 | 28 |
I was curious about other methods. Greg Lane wrote an excellent article on restoring found sets using snapshot links: Restoring a FileMaker Found Set Within A Server-Side Script. Another technique involves temporarily storing the IDs in a utility field and then using the Go To Related Record (GTRR) step.
I was curious about how these methods compared, so I did a bit of testing, but before we get to the results, the different methods merit a bit more discussion.
Step One: Collect Values In the FileMaker Found Set
In general, there are two steps involved: the first is to collect the IDs of the records in the found set, and the second is to recreate the record set.
I used to use a custom function to collect values from a field for all records in the FileMaker found set. One way to write such a FileMaker custom function is:
Signature: CollectValues ( field )
If (
Get ( FoundCount ) > 0 ;
Let ( [
$i_forColValCF = If ( IsEmpty ( $i_forColValCF ) ; 1 ; $i_forColValCF + 1 ) ;
iteration = $i_forColValCF ;
$i_forColValCF = If ( iteration < Get ( FoundCount ) ; $i_forColValCF )
] ;
List (
GetNthRecord ( field ; iteration ) ;
If ( iteration < Get ( FoundCount ) ; CollectValues ( field ) )
)
)
)
This approach has two limitations: The first is the 10,000 recursion limit that FileMaker has for custom functions when doing additive recursions. (The limit for tail recursions is 50,000.) The second is that it’s slow when the size of the found set is large.
Instead of doing this work via a FileMaker custom function, we could loop through the records and collect the values. This saves us from the recursion limit but does not gain us any speed improvements (and in fact may be even slower).
FileMaker 13 introduced the ‘List of’ summary field, which is a much faster way of collecting field values from FileMaker found sets. However, this approach requires you to set up a new summary field for every field whose values you want to collect.
The snapshot link affords us with yet another approach, although in this case what is collected is the internal record IDs. However, snapshot links are created even more quickly than ‘List of’ summary fields are evaluated.
Step One Summary
| Method | Speed |
|---|---|
| Custom function | Recursion limit, slow with large found sets |
| Loop through records | Slow with large found sets |
| ‘List of’ summary field | Fast |
| Snapshot link | Fast, even with really large found sets |
Step Two: Recreate Found Set
The second step boils down to two alternatives: using Perform Find or GTRR. But as usual, there are some caveats.
List of Find
If we are collecting the primary key values, the fastest way to do so is using the ‘List of’ summary field. Once we have this list of IDs, we can create a find request for each one and then do a Perform Find to restore the found set. However, this approach is quite slow when working with found sets that are bigger than a few thousand.
In my testing, I refer to this method as “List of Find”.
GTRR
Instead of creating find requests and using Perform Find, we can temporarily store the list of IDs and use the Go To Related Record (GTRR) step to recreate the FileMaker found set. However, as it turns out, it makes a difference if the ID is a number field or if it’s a text field. A number ID is typically set up to use the auto-enter serial setting, and a text ID typically uses the Get ( UUID ) function. When working with found sets that are larger than just a few thousand records, the GTRR step performs considerably more quickly if the ID is a number field. (And both varieties perform much, much more quickly than the List of Find method.)
In my testing, I refer to this method and its two variations as “GTRR (number)” and “GTRR (text)”.
Snapshot Find
If we use a snapshot link, then we can (very quickly) get a list of the internal record IDs. However, to make use of this list, we have to set up a stored calculation field that returns Get ( RecordID ). The basic sequence of this technique is as follows:
- Create the snapshot link file
- Insert the file into a global field
- Parse the contents of the file to get the internal record ID list
- Send the list to the server
- Create find requests using the stored calc field
- Perform Find
Snapshot Find: How many find requests?
Suppose we have a table with 10 records whose internal record IDs are 1 through 10, and suppose that our found set contains these eight records: 1, 2, 3, 5, 7, 8, 9, and 10. (Records 4 and 6 are missing.) The snapshot link would describe such a found set as follows:
| 1-3 |
| 5 |
| 7-10 |
So instead of having to make eight separate find requests, we now only have to make three find requests.
In the best case, the FileMaker found set consists entirely of records whose internal record IDs constitute a single continuous sequence. In this case, we only have to make a single find request.
In the worst case, the found set has no continuous sequence, and we have to make a separate find request for each ID. In my testing, I construct a found set like this by only including records with odd internal record ID values.
In my testing, I refer to this method and its two variations as “Snapshot Find (best case)” and “Snapshot Find (worst case)”.
Step Two Summary
| Method | Saving the Found Set | Restoring the Found Set | Considerations |
|---|---|---|---|
| List of Find | ‘List of’ summary | Perform Find | — |
| GTRR | ‘List of’ summary | GTRR | Number vs. text |
| Snapshot Find | Snapshot link | Perform Find | Best case vs. worst case |
Test Results
So how do the methods compare?
As I alluded to already, the List of Find method is quite slow. The GTRR method is fast, with number IDs performing considerably faster than text. The Snapshot Find method performs the fastest when the FileMaker found set is configured according to the ‘best case’, requiring just a single find request. But when the found set is set up according to the ‘worst case’, the performance is comparable to the List of Find method. (It’s a bit faster, because getting the list of internal record IDs from the snapshot is faster, but it’s still brutally slow.)
The answer is a bit unsatisfying, because for the Snapshot Find method, the data is shown for the ‘best case’ and the ‘worst case’, and not for the ‘typical case’. But the typical case would be difficult to reliably reconstruct in a test environment, so I had to resort to a best/worst-case type of analysis.
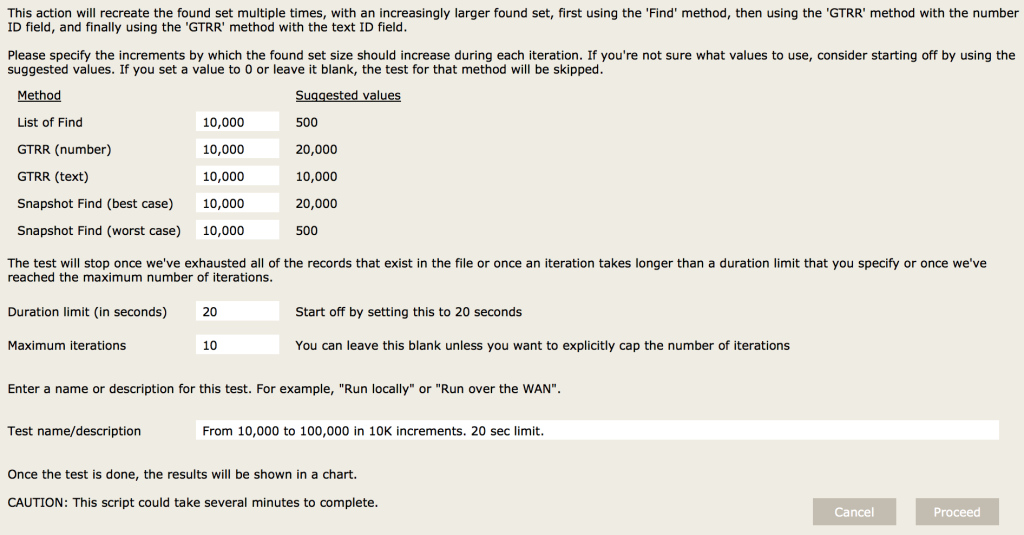
The test is set up to try each method multiple times, increasing the size of the found set with each iteration. Here are the results for found sets from 500 to 10,000 (in 500 increments):
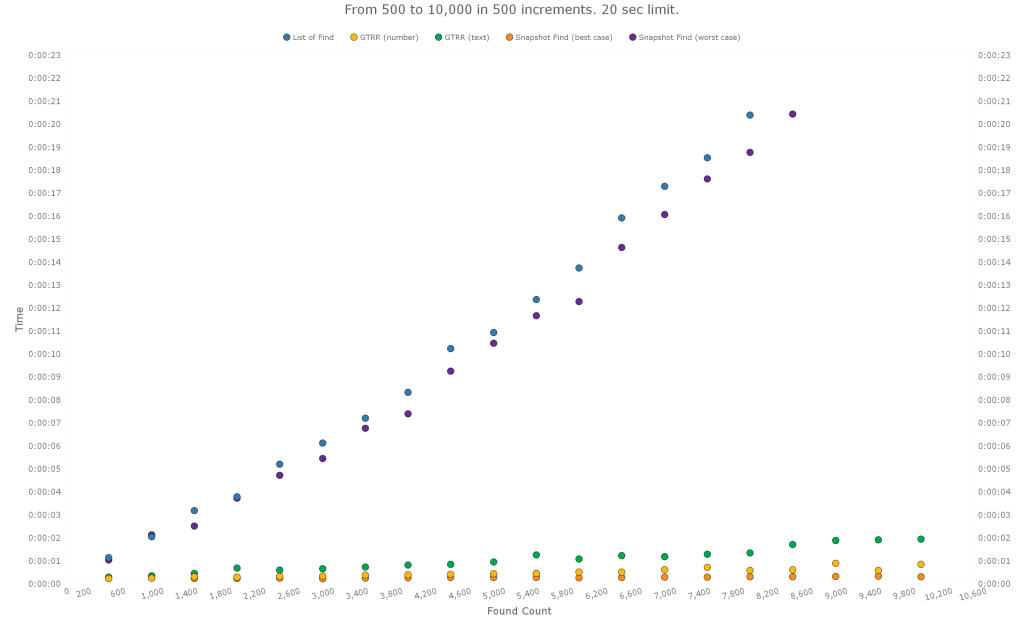
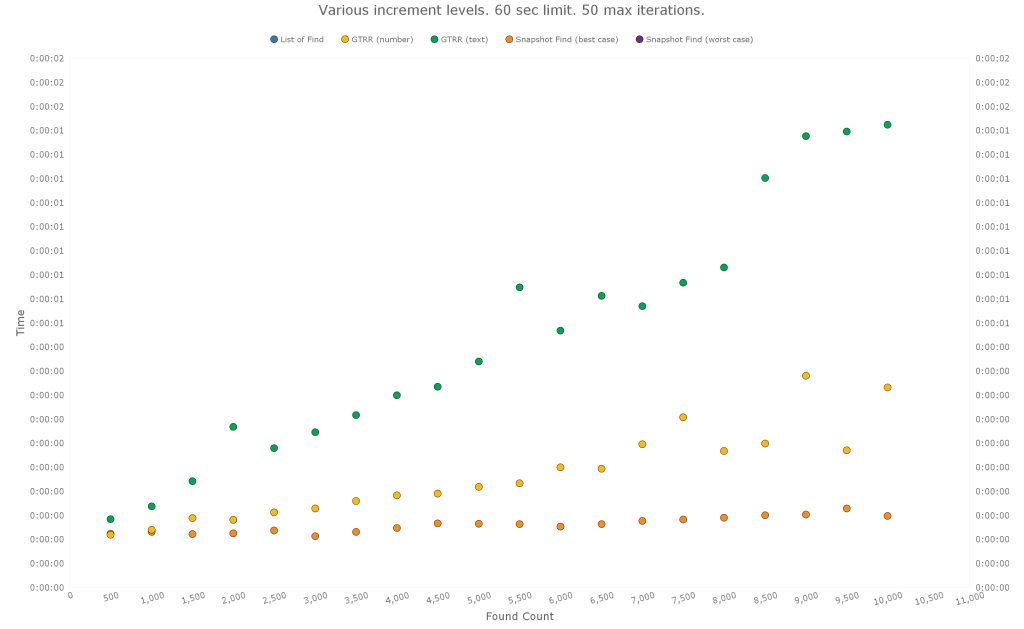
Here is the same data, with the List of Find and Snapshot Find (worst case) excluded:
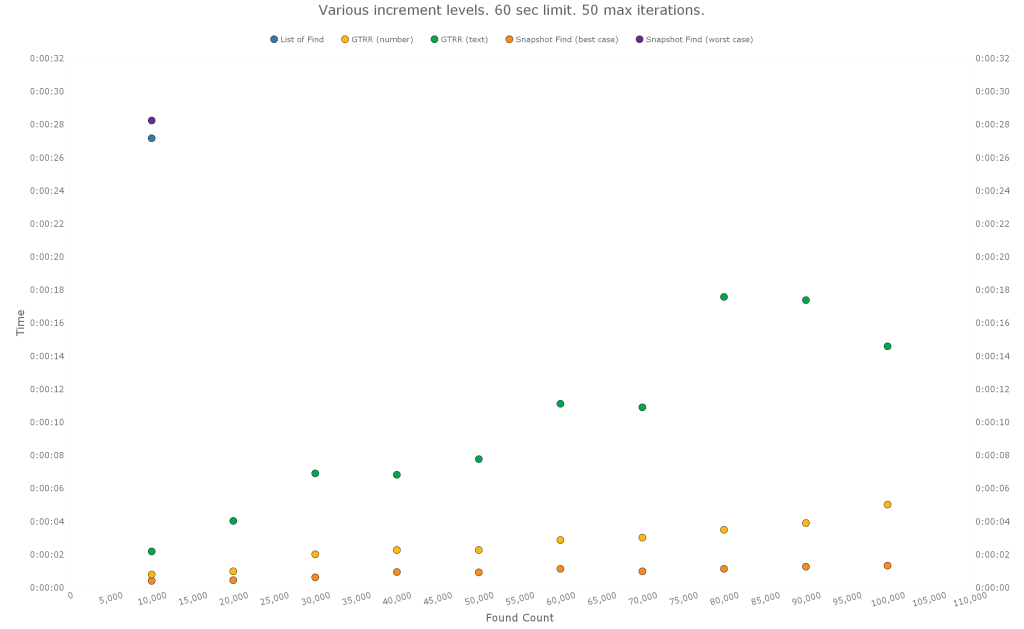
Below are the results for found sets from 10,000 to 100,000 (in 10,000 increments).
The test is set up to break out of the loop if a single duration lasts longer than a specified limit – in this case 20 seconds. That is why there is only a single data point for the List of Find and Snapshot Find (worst case) methods.
The same pattern seems to hold. Snapshot Find (best case) is still the fastest. GTRR is in the middle, with the number ID being faster. And the List of Find and Snapshot Find (worst case) are very slow.
Here are the results from testing found sets that are quite large and therefore probably fairly atypical. The increment levels were set differently for each method, and, for each method, the test was set to stop either after a single iteration exceeded 60 seconds or after it had completed 50 iterations. The same pattern seems to continue, although there is quite a bit of variation with the GTRR (text) method.
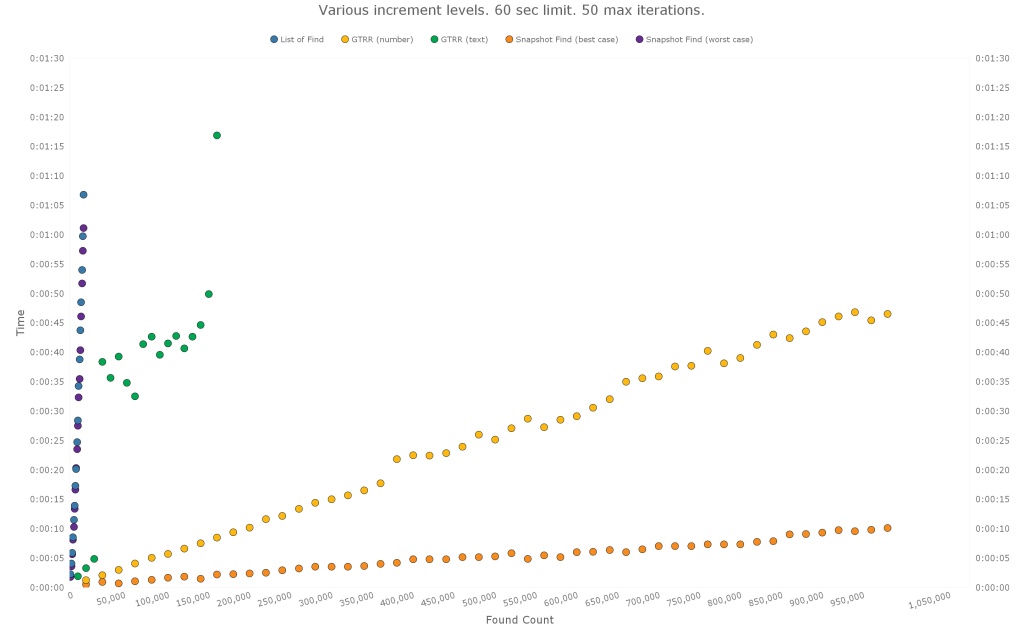
The GTRR (text) variation may have been due to latency hiccups, or the server may have been busy with something else during that time. During other test runs, the GTRR (text) method showed less variation.
Creating large numbers of find requests, as is the case with the List of Find and Snapshot Find (worst case) methods, seems to have an exponential growth characteristic. The GTRR method seems to follow a more linear progression. Here is a chart which shows this. (You won’t find this data in the demo file however, since it comes from an earlier version of that file.)

Which Takes Longer: Step 1 or Step 2?
The bottom line is the overall time it takes to recreate the found set. But it’s interesting to split the time into the two steps – collecting the IDs and recreating the found set – and see how long each one takes.
For the two methods that rely on find requests, the second step takes the most time. For the GTRR method, it seems to be more evenly split.
Demo File
If you’d like to run the test yourself, download the demo file. Create some test records, set the found set so that it contains a certain number of records, and then use the Ad Hoc buttons to try any of the methods.
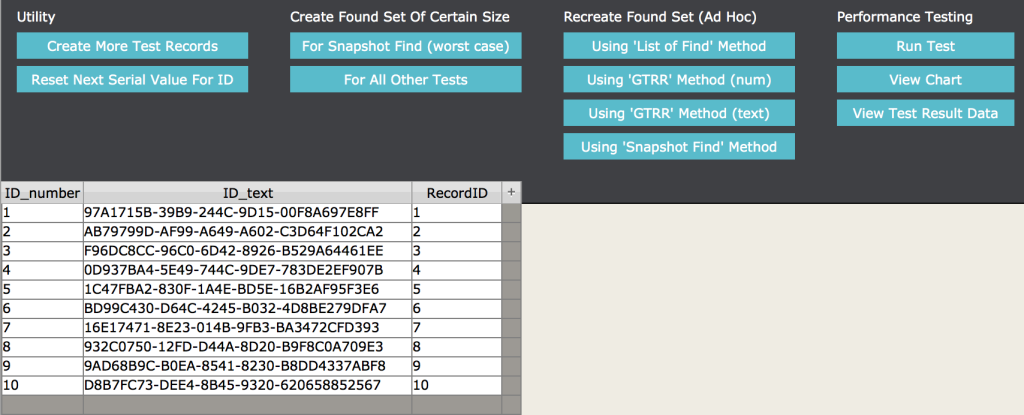
Alternatively, you can click the ‘Run Test’ button, which will loop through all five scenarios, increasing the found set in each iteration. The script will break out of the loop once we’ve used up all of the records in the table, or once a single iteration takes longer than a certain time (which you specify) to recreate the found set, or once it completes a certain number of iterations (which you also specify). If you do decide to run this test, you may want to create a sizable number of test records first. For example, you could bring the total number of records up to 1,000,000. This will give you a meaningful size to test with.
Caution: if you do run the test script, it could take a while to complete. For example, running the test with found sets set to go from 10,000 to 100,000 (in 10,000 increments) and using 20 seconds as the duration limit took about 10 minutes.
Here’s a screenshot of the window where the test parameters are configured:
Script parameter length limit for PSoS (error 513)
If you end up looking at the scripts more closely, you will notice that I am passing the IDs along to the server by storing them in a record. Initially I was passing them along as a script parameter, but since I was testing with large FileMaker found sets, it wasn’t long before I came across error 513, which is what Get ( LastError ) returns when the script parameter for Perform Script on Server exceeds 1 million characters. Note that the error description for 513 is “Record must have a value in some field to be created”; i.e. it’s not at all obvious what the error is for, and it took a bit of googling to find out.
Summary of Methods
| Method | Save Found Set | Restore Found Set | Considerations | Preparation | Speed |
|---|---|---|---|---|---|
| List of Find | List of summary | Perform Find | — | Create List of summary field | Slow |
| GTRR | List of summary | GTRR | Number vs. text | Create List of summary field and set up relationship for GTRR | Fast |
| Snapshot Find | Shapshot link | Perform Find | Best case vs. worst case | Create Get(RecordID) calculation field | It depends (fastest for best case, slow for worst case) |
Tangential Findings
I came across some unanticipated lessons while setting up and running these tests. However, these lessons only come into play when dealing with very large record counts.
Number vs UUID
Is it better to set up your primary key fields using auto-enter serial numbers or using text UUID values?
As part of my testing, I created 10,000,000 records in the main table. The table is otherwise quite narrow: there are no extraneous fields; just the ID fields. And yet the file size swelled from a few MB to 2.35 GB. In contrast, the size of a text file containing 10 million UUIDs is 370 MB. So clearly there is quite a lot of space used up that is in addition to the actual field contents.
Aside from the file size implication, as was pointed out earlier, performing a GTRR step using a text ID runs more slowly as compared to number ID fields. Here are some results from one of the tests. Note, the times shown include both evaluating the List of summary field and executing the GTRR step.
| Found Count | GTRR (Number) | GTRR (Text) |
|---|---|---|
| 200,000 | 27 seconds | 40 seconds |
| 400,000 | 37 seconds | 85 seconds |
| 600,000 | 48 seconds | 127 seconds |
| 800,000 | 61 seconds | 171 seconds |
| 1,000,000 | 127 seconds | 218 seconds |
If your solution has (or has the potential for having) clients syncing an offline copy of a file with a hosted file, then you have to use UUIDs. But if you are dealing with large record counts, and you do not have to worry about syncing records, then you may be better off using number IDs.
Is There a Limit to a Multi-Line Key or to the List of Summary Field?
In trying out the ‘GTRR’ method, I was curious if there would be a limit to the number of values that a multi-line key can have. I haven’t been able to find a firm answer to this question online. So I created 10,000,000 records and tried it out with the file opened locally (i.e. not hosted).
The short answer is that there is a limit for the GTRR step, and in fact, there is also a limit to how many values the ‘List of’ summary field can handle. However, the exact nature of this limit isn’t clear. Neither will give an error; they will simply function incorrectly.
When I tried recreating a 10,000,000 record FileMaker found set using the GTRR (number) method, it worked, albeit slowly. The GTRR step took 4.6 minutes when run locally.
With the text ID field, the recreated found set was 7,805,664 records, even though the starting point was 10,000,000 records. It took 31 minutes, and no errors were indicated, even though things didn’t work as expected.
I ran this test a second time, and the resultant found set was once again 7,805,664 records, this time in 30.5 minutes.
When I ran it a third time, I got 7,807,436 records in 31.5 minutes. Of these 31 minutes, it took 23 minutes to compute the list of ID values, and the GTRR step itself took 8.5 minutes. Not all of the values made it into the list either; the list had 7,807,444 values. (I didn’t check for this the first two times.) This means that neither the ‘List of’ summary field nor the GTRR step functioned correctly.
Running the test a fourth time resulted in 7,805,664 records in 30.5 minutes. The list of IDs contained 7,805,672 values. Gathering the IDs took 22 minutes, and the GTRR step took 8.5 minutes.
| Test | Original Found Count | Count of Values in ‘List of’ Summary Field | Resultant Found Set After GTRR | Delta | ‘List of’ Time | GTRR Time | Total Time (mins) |
|---|---|---|---|---|---|---|---|
| 1 | 10,000,000 | — | 7,805,664 | — | — | — | 31 |
| 2 | 10,000,000 | — | 7,805,664 | — | — | — | 30.5 |
| 3 | 10,000,000 | 7,807,444 | 7,807,436 | 8 | 23 | 8.5 | 31.5 |
| 4 | 10,000,000 | 7,805,672 | 7,805,664 | 8 | 22 | 8.5 | 30.5 |
— means “not measured”
Have You Outgrown FileMaker?
Evaluating a ‘List of’ or running a GTRR step when dealing with millions of records in the found set is very much an outside case; it is not typical. And if you are dealing with this situation, it may be that you have outgrown FileMaker. So the uncertainty of this not functioning correctly is likely irrelevant to your situation. However, I am including my findings here, because it still is a conceivable situation, and it might turn out to be useful information for some of you.
Optimizing The Script
An obvious optimization would involve the case when the FileMaker found set is showing no records or when it’s showing all records.
If we are dealing with large record counts, there is another simple optimization that we can do. If the found set that we will recreate is more than half the size of the table (the total number of records in the table), then recreating the flip side of the found set will be faster, and once we’re done, we can flip the found set again to show omitted records. (The script would also need to exclude any new records that may have been created since the script started executing.)
The demo file does not do any of these optimizations, but they would be simple enough to implement.
Lastly, if you are dealing with a workflow that requires PSoS processing and where the found sets are typically large, it may make more sense to pass along the search criteria to the script and recreate the find there instead of passing along the IDs. It may not be possible or feasible to do this, but if it is, that may be the better approach.
Test Environment
The testing was done using FileMaker Pro Advanced 13.0v5 on a MacBook Pro (10.10.2) and FileMaker Pro Advanced 14.0.4 on an iMac (10.11.3). I ran the tests first with the file opened locally and again with the file hosted on FileMaker Server 14.0.4.413 and accessing it over the WAN.
Moving Forward with FileMaker Custom Functions
Our team of FileMaker developers and consultants can help you leverage FileMaker custom functions like the FileMaker found set to improve your business application. Contact us to talk with a consultant today.
Hi, terrific info, thanks to post it. 2 remarks :
– The fact that Lisog an GTRR are unreliable is a bug and should be reported as such to FMI. It’s a bug because that’s undocumented behavior with no precise limit, moreover if It’s in the limit of a field contents, it should work perfectly
– I don’t understand why you didn’t use the Snapshot link, with GTRR for the foundset recreation. I mean, parsing the snapshot link, putting the result in a global filed and then GTRR.
Hi Vincent, thanks for your comment.
Why didn’t I use a Snapshot Link/GTRR combo? Because I didn’t think of it 🙂
It’s an interesting idea. The Snapshot Link gives you internal record IDs in ranges; for example, 1-3, 5, 7-10. Using a range value like 1-3 (or 1…3) won’t work with a relationship. We’d have to convert it to 1┬╢2┬╢3 first. This would make the virtual left of the relationship contain as many values as there are records in the found set, which is the same as how the “GTRR” method works. So there would be no speed improvements in the second step.
However, for large record counts, the Snapshot Link is faster than ‘List of’. So that part would be faster. But then all of the internal record IDs that are represented as ranges would have to be converted into a standard list, which would take some time to do. (And, due to the recursion limit, this would need to be done in a loop in the script as opposed to using a custom function.)
It would be interesting to see how this would perform.
Hi Mislav,
Great stuff…thanks for sharing! A few points worth considering:
The non-snapshot tests will be artificially fast if you don’t close the file between tests. Once the FileMaker client has retrieved a record’s data from the host, the data is available locally in the client’s cache. Subsequent tests will be MUCH faster than the initial test when those same records are involved.
The non-snapshot tests are also likely to be much slower with tables that are “wider”…containing more fields and data per record. The FileMaker client will retrieve all of the non-container data from the records that are included in the found set…not just the key field. This can have a big impact on these techniques in “real world” situations.
The snapshot method has the advantage of performing consistently regardless of the width of the table or whether or not the record data has been previously cached. This is due to the fact that a snapshot link file can be created for any found set without requiring all of the record data to be transferred from the server to the client.
Again, terrific post and I sincerely appreciate you sharing your research.
Greg
Greg, that’s some great info. Thank you.
Regarding the impact of wider tables: So does that mean that ‘List of’ downloads the entire found set just as would happen if we looped through each record? I wasn’t sure how that worked. I was hoping that FileMaker would send the values for just the field that the summary field is based on instead of retrieving all record data.
Hi Mislav,
Great work! And thank you for taking the time to put all of this together. I have a question about how you setup the List of Find and the Snap Shot Find processes. I’ve requested the demo file to review, but have not received it yet.
In my own experience I’ve noticed that creating a find for each ID goes MUCH faster when done on an empty (no fields) form view layout. There is something about putting the cursor in a field or displaying the fields (even in find mode) that dramatically slows down that process. I have no doubt that the overall findings would be the same, but perhaps “List of Find” and “Snap Shot Worst” are marginally better than portrayed with a layout modification?
Thanks again, I really enjoyed your article.
Chad and I exchanged emails discussing things a bit further, but for the benefit of anyone else who may be reading these comments:
ΓÇó In general, using a blank layout seems to perform better when work is done on the client, but it’s unclear if it will be helpful in this case considering the finds are happening server-side.
ΓÇó Chad pointed out that the “List of Find” method can be significantly optimized by changing the loop that restores the found set (by creating find requests) so that the ValueCount function is called just once instead of during each iteration of the loop. Chad tested this out with a 12,000 record found set, and the script was twice as fast. Nice catch!
ΓÇó Chad also noted that entering find mode before switching layouts will eliminate the unnecessary loading of a record (or, if you’re in list or table view, multiple records). As he points out, this won’t make a game-changing difference with the kinds of tests being done here, but it’s a good tip, and every little bit helps.
Thanks Chad!
Mislav, yes, “List of” summaries do download all of the data for the found set. I tested this in your sample file by adding a text field to the Contact table, creating 50,000 records, and then putting 200 million characters* into the text field in one record toward the end of the table. Using a found set of the first half of the records, the IDs were gathered in .865 seconds (and then .121 seconds on subsequent tests). Using a found set of the second half of the records (including the record with the large amount of text), the IDs were gathered in 15.367 seconds (and then .121 seconds on subsequent tests). FileMaker Pro even displayed a ‘Summarizing field “zz_ID_number_list_s”‘ progress dialog while the script ran.
I hope someone will chime in with a clever optimization, but I’m not aware of any method to gather the values for a primary key field from a found set on a client without downloading all of the data (for all non-container fields) for the found set.
Greg
* I was testing with a local server, so I used an extreme amount of text to amplify the issue. With a remote server, the issue should be reproducible with a much smaller payload.
hi Greg, do you know if snapshot link also does download the whole record data ?
Hi Vincent,
Saving a snapshot link doesn’t seem to download record data. Here’s what I did to check:
I opened the hosted file and checked the temp file that gets created when a database file is opened. This temp file is located one level up from the directory indicated by Get(TemporaryPath).
There were two temp files there:
(1)┬áFMTEMPFM4160_1.tmp – This file was created as soon as I started FileMaker Pro, before I even opened the database file.
(2)┬áFMTEMPFM4160_2.tmp – This is the temp file for my database file, and it’s size was 12 KB at this point.
I saved a snapshot link, and FMTEMPFM4160_2.tmp grew to 766 KB.
I then set the found set to 100,000 records, evaluated ‘List of’ by placing the zz_ID_text_list_s field in the Data Viewer, and the temp file grew to 13.7 MB.
Thanks a lot Mislav, what a shame list_of loads all the data
Please see my related Ideas I submitted to FMI (and hopefully vote for it ;-))
https://community.filemaker.com/ideas/1779
https://community.filemaker.com/ideas/1765
Mislav,
Great article. Thanks for all of the time trials. Very useful info.
One thing that I was going to add is that if you need UUIDs, you are not limited to FileMaker’s built-in text-based UUID function. We use a custom UUID function, that is based on Jeremy Bante’s UUIDTimeDevice function, found at http://filemakerstandards.org/display/bp/Key+values to generate a number-based UUID. The reason we chose that was because of the findings that FM can process numbers faster than text, as you also show here.
It is a much larger number than most serial numbers, so you might lose some performance, but I think it should still out-perform text-based UUIDs by a long shot.
Thanks again!
-Shawn
GTRR uses a field’s value index, so mostly it’s the length of the primary key, not it’s field type, that will have greater affects on speed. https://www.filemaker.com/help/14/fmp/en/html/create_db.8.28.html
In a table with 10,000,000 records, primary keys made of:
For hosted solutions I remember someone posting a technique to use an unstored calc to get a summary list of Get(RecordID) (so you wouldn’t have to pull down the entire record), and then an indexed field with Get(RecordID) to use for GTRR.
I ran some tests for Summary As List + GTRR in a local file from 10,000 – 500,000 records:
For 500,000 Records:
Thank you Michael – this is more good info. Good point about the key difference being the length of the primary key value rather than the field type.
I don’t follow the part about using an unstored calc though. How would you get a summary list of Get(RecordID) this way, and why would this approach not pull down the entire record?
I’m curious: Under what specific circumstances do you feel that you need to re-create a found set on the server? What are some of the use cases?
I presume what you mean is that you have found records on the client and you now need to push that found set back to the server.
One example is if you store or cache a value in a field, for example a count of related records, and then you need to refresh the stored values for a set of records, because some of the related records were deleted. You could do this on the client, but it may make sense to offload that work to the server via the Perform Script on Server step. But in this case you need a way to communicate to the server which records need to be updated.
Another approach to gathering record ids is to place your record ID field onto a separate layout and use the Copy all records script step. Its fast. The downside to this approach is the required layout navigation and the clipboard destruction (overwriting the users data that they may have copied) which can be handled by a plugin that can capture the clipboard data and restore it.
To expand on the method Brian Currell mentions to gather ID’s – a method we used the last 15 years or so – we first paste the clipboard into a global container field on a specific layout, then gather the ID’s, do what we want to do with them, and then restore the clipboard by copying the container. Just two simple scripts.
Another reasonably fast way to gather ID’s is the ‘fake replace’ method:
replace[ let(
$IDlist = list( $IDlist ; ID )
; “” )
Much faster then a loop.
By the way, I think we got both ideas from Michael Edoshin.
Re: unstored calcs and FileMaker Server:
Daniel Wood in a comment on http://www.modularfilemaker.org/module/hyperlist/
“The method goes as such ΓÇô add an unstored calc to your table that contains get ( recordID ). Also add a stored version of the calculation. Now, if you tried to obtain the stored version of the calculation then it acts just like any piece of stored data on the record ΓÇô and FileMaker Server will send you the whole record. BUT, if you grab the unstored version of the calculation, FileMaker Server is somehow designed in such a way that it can send you just the record ID without sending you the entire record itself (maybe through index or some other means). And itΓÇÖs FAST, VERY FAST!”
Video by Todd Geist
https://www.geistinteractive.com/2013/11/11/master-detail-get-record-id/
Thank you Mislav! This really helped me a ton yesterday! And exactly a year after you posted it 🙂
Thanks a lot for this info guys, I’m going to test some tecniques now!
Your work is highly appreciated. Thanks so much!
Good post, Mislav Kos. The two steps to recreate the FileMaker found set are nicely explained. The summary of the time taken in each step is given in tabular form. You can easily compare. The optimization of the script and the testing are a must steps to do. Good information.
Oh my god, 4 years here and i didn’t see this super track. Thanks a lot.
I use the unstored recordID approach consistently.
4 fields in every table – a stored Get(RecordID) and an unstored Get(RecordID), a Listof summary field (the unstoredRecordID) and a global match field to script the result of the ListOf summary field.
As the unstored RecordID is apparently in memory for whatever the current found set is, gathering it with a ListOf Summary is extremely quick, even over a slow WAN connection (as Daniel Wood indicates in his comments on using this technique).
The stored Get (RecordID) is there to allow the match to a stored result from the global that is scripted from the summary listOF, and a GTRR gets you to that found set.
You can store that ListOf at any point of the process and use it to return to that set, using this approach. It works great for passing the found set from one window to another, say a card set up to do a FIND, using the same context as the UI window.
And the best part, is that is universal, modular code that can be used with any table, with the same code base, same field names, varying context.
I can’t believe we’re still having to go through all this hassle to recreate a found set on server.
Shouldn’t we just be able to create a snapshot link and hand it to the server to open?
Better yet, Perform Script on Server should just have a checkbox, “Use current found set.”
>> Perform Script on Server should just have a checkbox, “Use current found set.”
I love that idea. Here’s a similar one which you could vote for if you haven’t already: https://community.claris.com/en/s/idea/0870H000000fy0EQAQ/detail.
Or you could create a new suggestion specifically for the idea you had. If you do, please post back here so the rest of us know to vote for it.