My co-worker Sara and I got to talking about our guilty fondness for Lifetime original TV movies. Apparently, we’ve both watched our share of those Saturday afternoon tear-jerker stories, where someone makes a melodramatic plea to their love interest, while somebody else is fighting off cancer, and all the actors look vaguely familiar because they were either famous fifteen years ago or you saw them a couple of weeks ago in a different TV movie. Sara pointed out one of the best (worst?) things about these movies: their titles.
I discovered that, on Lifetime’s site, they offer a listing of their entire movie directory. Almost two thousand titles, nicely formatted and ready for scraping, and almost all of them wonderfully awful. Titles that, like the movies themselves, try so hard to evoke pathos that they have almost the opposite effect, like: “A Touch of Hope”, “In Spite of Love” and “The Stranger I Married” (Originally, in Canada, the title for this film was “The Man Who Lost Himself”— someone actually thought enough about this to change the title for the US market).
I couldn’t let all this data go to waste. I thought it would be fun to build a Lifetime movie title generator, using the list of titles from their movie directory. My goal was to write a piece of code that would be able to generate strings that could pass for original titles of Lifetime movies. I was going to use statistical information gleaned from the title corpus to rearrange and piece together words from these titles into new, similar sounding titles. The resulting solution uses Javascript to do the generating.
Here is a list of titles which includes both real movies that Lifetime has aired or will air and also titles generated by the title generator. Can you tell which ones are real and which ones are generated?
| A Crime of Love and Innocent Victims | First, Do No Harm |
| Why I Want to Heal | Honeymoon with Mom |
| Dirty Little Man With Harmful Intent | Moment of Truth: Cradle of Conspiracy |
| Another Man’s Wife He Forgot | Dying to Remember |
| One Hot Summer House Of Deceit (2006) | When Billie Beat Bobby |
| A Nightmare at 17 | The Party Never Stops |
| Amber’s Story of the Shadows | Murder or Memory? A Moment of Truth Movie |
| Dr. Quinn: The Perfect Alibi |
The ones on the left are fake, the ones on the right are actual titles.
To begin, I wrote a quick script to scrape the data from Lifetime’s site. Their listing pages were machine generated, so the content was easy to locate programmatically. I won’t cover the script I used to scrape the data (maybe in a future blog post), but you can find the results here in text format. There were 1,968 titles scraped from 132 pages.
My plan was to use a mathematical structure called a Markov chain to model the statistical likelihood of a word in a title being followed by some other word in a title. Then, I could use that statistical information to generate new titles by choosing the first word (at random) and then choosing subsequent words with a frequency proportional to how those words are arranged in the original text. This will give me a string of text that may not be in the original text, but will share stylistic properties of the original text. While my first approach to writing this generation code did explicitly compute the statistical properties as described above, I later decided to avoid these explicit computations with the trade off of a little bit more memory usage but much cleaner code. The code and the compromise will be explained below.
As an illustration of how this Markov chain model might look for this list of titles, consider this small subset of titles:
- The Christmas Wish
- The Client
- The Client List
- The Clique
- The Cold Heart of a Killer
- The Colony
- The Color of Courage
- The Color of Love: Jacey’s Story
- The Color Purple
- The Con
We begin by constructing a list of unique words that appear in these titles: “The”, “Christmas”, “Wish”, “Client”, “List”, “Clique”, “Cold”, “Heart”, “of”, “a”, “Killer”, “Colony”, “Color”, “Courage”, “Love:”, “Jacey’s”, “Story”, “Purple”, “Con”.
Next, for each word in this list, we count which words follow that word and with which frequency. For example, the word “The” is followed by “Christmas”, “Clique”, “Cold”, “Colony” or “Con” 10% of the time, followed by “Client” 20% of the time, or “Color” 30% of the time. In any text generated from this corpus, we should expect the same statistical properties to hold, if we want to maintain a similar style and feel as the original sample.
Here is the full graph of probabilities for the above sample text. Here, each vertex represents a word that appears in the corpus. For each word, when that word is followed by another word, the probability that this occurs is represented by a labeled directed edge between those vertices.
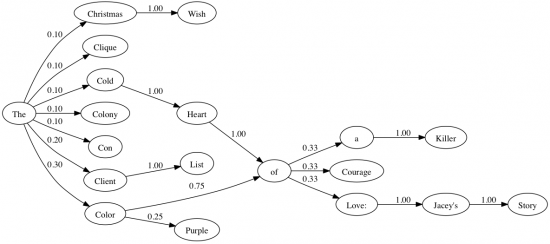
Using this picture, we can try generating a few words by choosing to start with the word “The” and for each new word desired, we’ll roll a die and decide which next node to move to accordingly. Some possible generated strings include each title from the original list, but also the new titles “The Color of a Killer” or “The Cold Heart of Love: Jacey’s Story”. With more data, a more complicated graph can be constructed, and more interesting and varied strings can be generated as a result. You should use as much data in your corpus as you can find!
That’s roughly how the text generator works in general. However, I avoided computing the probabilities for each word by instead storing a list of every word following each word (including duplicates). Choosing from this list at random will have the same consequence as rolling a die and choosing the next word from a stored list of probabilities, but this way I don’t have to go through the trouble of computing those numbers or the cost of making a bunch of floating point comparisons for each word.
Here is the code. Note that titles is an array of strings already defined with the corpus list of titles:
At the start, I initialize the object that will store the list of words as properties, with the values being a list of words that have been known to follow that word (preserving multiplicity). I also initialize two other structures which I use to keep track of which words are found at the ends of titles and which words are found at the beginning of titles. I do this because after some tweaking, I found that I can get subjectively better results if I have my generated titles also start and end with those same words.
Then, I begin building the wordstats database. For each title, I take note of which words appear at the start and end. I store the terminal words as properties on an object rather than values in a list because I only care about the unique list of words and I know that I’ll only ever use this list to check for inclusion, so this way is faster than looping through the list or using indexOf(). Then, for each word in each title, the code simply initializes or adds to the list of words following a given word, which is stored by key in the wordstats object. That is pretty much all that needs to be done to embody the statistical relationship in the sequence of words in the original titles.
Next, I define a little helper function. Given an array, I would like to have returned a random element from that array.
Finally, I define the actual function to generate titles.
I parameterized this function based on minimum number of words that should be included in the title, because after some testing I found that shorter titles either did not make sense or were too often real titles from the corpus. Most of the function works to try to build a list of words for that title up to the minimum length, but sometimes that isn’t possible because too early on a word is reached that does not have any following words in the corpus. When that happens, a line at the end of the function catches it and just starts the whole process over again (actually it recurses, but I do this with confidence that an appropriate title is very likely to be generated sooner rather than later— this could also be done by wrapping most of the function in another while loop).
The function begins by choosing a word at random from the list of known start words. Then, as long as there are words that have been known to follow that word, it chooses one of the following words at random (exploiting the fact that this list of following words preserves multiplicity and so a random choice from the list is representative of likelihood in the corpus). Once the minimum word length is met (if it can be met), the function will keep adding words but will now start checking for words that are known to have occurred at the end of a title, so that it can preserve that property for the generated title.
These little tweaks (setting a minimum length, choosing to start with start words and end with end words) are all adjustments I made because I felt that these changes improved the subjective quality of the resulting titles. If you are planning on doing something similar, you may want to start by not including these tweaks and deciding on how to improve the quality yourself.
That’s all there is to it. I find that titles with a minimum length of about 3 to 5 words works out nicely. To aim for roughly that length, I call the make_title function with code that looks like:
var title = make_title(3 + Math.floor(3 * Math.random()));Try it for yourself by clicking the Generate button:
Please tell me what day and time "Dirty Little Man With Harmful Intent" airs.
Great article!
Holy fuck, good to see that your markov chain take into account what words start title and what words end title, a thing a extreme amount of guys doing it forget.
Anyway, your markov chain generator, generate the title starting with the “title start” word by default.
A better idea, would be to generate the first word at random (including “title start” words and “title ends” words), if the first word you generate is not a title start word, you need to generate words before this word until you generate the title start word. Then you continue to generate words after the first one you got (unless the first word you generated was a “title end” word), until you generate the “title end” word
Kmone,
Are you suggesting to pick a random seed word then choose words from the Markov chain data to find preceding words, until I read a start word? That is a very interesting idea, and I don't think I've seen that done before.
The way I built my Markov chain, though, the data about frequencies of which words precede a given word isn't calculated or stored. The Markov chain data only has information about the frequencies of which words follow a given word (notice the arrows in the graph diagram all point to the right).
It would certainly be feasible to alter to code to make the Markov chain bi-directional, though (so that the arrows in the graph between nodes point in both directions). Maybe you can make a copy of my JSFiddle and try it. I'd be interested to see what you come up with.
Thanks for commenting on the blog post!
-Jason
@Kmone,
This is commonly referred to as backwards and forwards chaining. However in this particular instance it seems like a lot of work with no real value added. His program generates titles completely randomly whereas the primary advantage of backwards and forwards chaining is to allow you to seed a chain with a particular keyword.
@jbury,
If you’re interested in examples of bidirectional markov chaining I suggest you take a look at the chat bot, MegaHAL, which extracts a keyword from the users input to generate a relevant reply chain.
why don’t you create a program that uses markov chains to generate readable articles based on a set of keywords and sell it to seo people? you’d make a fortune in renewals and rebills.
Cool do the variations go on forever and ever? and is this possible to add to blogspot? thanks
Pingback: Appliance Science: How Alexa learns about you - CNET -
Pingback: Appliance Science: How Alexa learns about you – CNET – G Email News
Pingback: Appliance Science: How Alexa learns about you - CNET - سایت جون ، سایتی متفاوت site.jon.ir کوتاه کننده لینک
Pingback: Appliance Science: How Alexa learns about you - Artificial Intelligence Online
Neat concept.
wow- megaHAL is too cool. Thanks for that suggestion
The code and the generate button are not showing up. Would be great if you cold fix that because I am very interested in this topic.
Ditto last comment – would love to see the code.