macOS, iOS, and iPadOS have built-in capabilities that can execute Machine Learning models on FileMaker Pro and Go.
Machine Learning or ML falls under the broad umbrella of Artificial Intelligence. An ML model is built on a set of known training data so that it can then make predictions about what is in other similar data. For instance, it is used to scan emails and determine which ones are spam or to detect objects in pictures and video.
Machine Learning integrations are certainly not new in the FileMaker community. Many online APIs are available and have been demonstrated in past Developer Conferences and discussed in blog posts. Here at Soliant, we are heavily into Amazon Web Services; integrating with image and text recognition through Rekognition and Textract, to name just two, are second nature to us.
But there are good reasons why you could not or would not want to use any of these online services. Perhaps your app needs to be fully self-contained and cannot reach out to the internet. Or you want something that is as fast as possible, and running the routine locally is the only acceptable answer. Perhaps there are security constraints that do not allow your data to travel outside of your application. And of course, there is the cost: some of those online APIs are not free, whereas using the capabilities of the OS is.
If your app is deployed on Apple hardware, then you can use the macOS and iOS/iPadOS native Core ML features with FileMaker Pro and Go. This particular feature does not work on Windows, and it is also not compatible with WebDirect, Data API, or other APIs. It is partially compatible with server-side script execution in that it works only if the server is macOS.
Here is how it works. First, you need a machine learning model that is fully trained to do its job.
This blog post will assume you have one. Apple has a lot of documentation on how to create such a model, or convert models from other environments to the Core ML format. Creating and training a model is not a trivial undertaking, and often, you will want to look for a pre-built model to use. You can find some pre-built models to test with. It is likely, however, that you will only get the best result for your specific use when you create and train your own model.
Note that not all models that you will find will work in FileMaker since FileMaker supports only a subset of everything that Core ML can do. Mainly FileMaker lets you classify images and text. The output of the model has to be text or numbers, but not complex data types or images. In FileMaker, you can use such a model, but not create or modify it. The model will not learn and improve itself from your FileMaker data by running it.
Once you have a working model, you store it in a container field in FileMaker.
FileMaker 19 has a new script step and a new function. The Configure Machine Learning Model script loads the Core ML model from the container field.

The script step has three possible operations:
- Unload clears the model from memory and frees up the resources. You would typically call this when you have no use for the model anymore. Since some of the machine learning models are pretty big files, this is something you may need to do judiciously, especially on your mobile devices.
- Vision indicates that the model is about image classification
- Choose General when the model is about text classification
The step also sets the name of the model so that you can refer to it by name later, and it points to the container field where the model is stored.
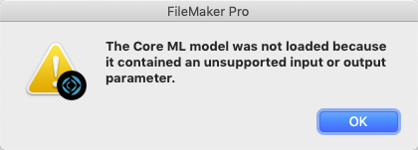
If the model is not supported, then you can expect an error 872 like this one. Usually, this will be because the model requires an input that is too complex or outputs something that FileMaker is not prepared to handle.
At the point in your workflow where you need to invoke the model, you use the new ComputeModel() function.
The syntax for this function differs a little depending on whether you use image classification or text classification.
When you have an image and a model that will describe, you can optionally specify parameters such as threshold and returnAtLeastOne that are not available with a model that processes text:

threshold is useful because some models can provide an output that contains thousands of answers. In most cases, you just care about the top few answers, and this option makes it possible to constrain the output to just those answers whose probability exceeds your threshold. In case none of the answers meets your threshold, by specifying returnAtLeastOne you will get the top answer even if it does not make your threshold cut-off.
When the model is all about working with text, you should use the function like this.

The function does not describe what the text interpretation will be, that really comes down to knowing what the model is all about.
The function always returns JSON, so you will have to parse the result for it to be useful in your app.
Example 1: Movie Reviews
The screenshot below shows a model that is built around labeling movie reviews.
Input_gt holds a movie review, and the script classifies the movie as good or bad based on its interpretation and analysis of the review:


Example 2: Image Analysis
The SqueezeNet model looks at an image and returns an array of possible keywords with a probability assigned to each one. It is executed by this script:

And produces this result:

Finding or creating a good model is, of course, crucial to the desired outcome. If you have any questions on using Core ML or any of the available online APIs that involve machine learning, then certainly do .
[…] Not being a computer developer, and merely a user, with a weak background in that area, does it make sense to, in this context, migrate into a sophisticated new application sustained with attributes that i am afraid I wont use in a responsible and mature way?
Hi Carlos,
We do believe that FileMaker 19 significantly changes how solutions will be built going forward. The way that the native JavaScript support has been implemented opens up a new world for all level of developers.
I agree. I am using a trial version of Filemaker Pro 19 and I am very well impressed.
As I have two computers, I am thinking serously havin new applications.
Thank you very much.
Can FileMaker work with object detection models created in the create ML app?
It should since the Create ML app is basically a wrapper around the ususal workflow of creating an ML model with XCode. The end result is a .mlmodel file. The main constraint is to use simple data structures for the output.
So from what I can understand, Filemaker will work only with models that are using supervised learning for ex. classifications, but models such as
similarity is not possible to implement?
If the model adheres to the ‘simple data structures’ restriction then it could work; the best way to find out is to try.
If you find that it does not then make sure to post in the “Ideas” section on community.claris.com and also create a regular post in that community to draw attention to your idea so that people can vote it up.
A typical way around this would be to set up a small web service (micro-service) that can use your model and call that micro service from inside FM. That would have the added benefit that it would work cross-platform as well.