GeoJSON data contains many properties which can result in large object size. When dealing with large collections of GeoJSON in your FileMaker solution, your JSON file size can balloon, causing the JSON parsing functions to choke and crash FileMaker when you try to work with GeoJSON (or any large collections of JSON).
There are two techniques you can use to optimize manipulation of large arrays of JSON.
We’ll use two different file sizes as example data — one representing all zip codes in Rhode Island (1.7 MB) and another for those Texas (80.1 MB). Rhode Island is a better choice when you’re experimenting, and Texas is a good one to use for load testing and benchmarking.
Get the Demo
Download the demo to follow along.
Preparing The Data With Primitive Text Manipulation Functions
The first step for both options is to use FileMaker’s primitive text manipulation functions and split the collection up into a value list, with each value representing one object in the group. This basic optimization makes it possible to manage such large files, but it does have some drawbacks to be aware of.
The main drawback of this technique is that it relies on the specific white space format and potentially the particular property order of the input object. These are both supposed to be arbitrary in valid JSON. You don’t want to have to rely on them, but often the source of the collection is from a known automated source. If this is the case, we can reasonably risk relying on arbitrary aspects of the input file, which a JSON validator doesn’t enforce.
Defining a primitive text parsing function to split up an array is fast and generally not very complex. Once done, it allows much more efficient parsing of the input value-by-value. Even if each value is a reasonably large and complex object, most parsers, including FileMaker, are better able to process them one-by-one sequentially rather than trying to load them all into memory at the same time.
Loading The Collection as a Records
Let’s walk through a situation in which we want to load the source files into FileMaker as a table of records and look at a subset of the properties. We also want to be able to manipulate the data (add new metadata property) and then save it back out in the original format.
In a GeoJSON collection, a single instance object is called a Feature, and it contains many properties. We’re interested in a handful of identifying properties.
Once we finish our data manipulation, we want to save out the data in the original format, with our one new metadata property added to each one.
Here’s a screenshot of our Manipulator table. Note that we have a field called GeoJsonFeatureObjectInput.
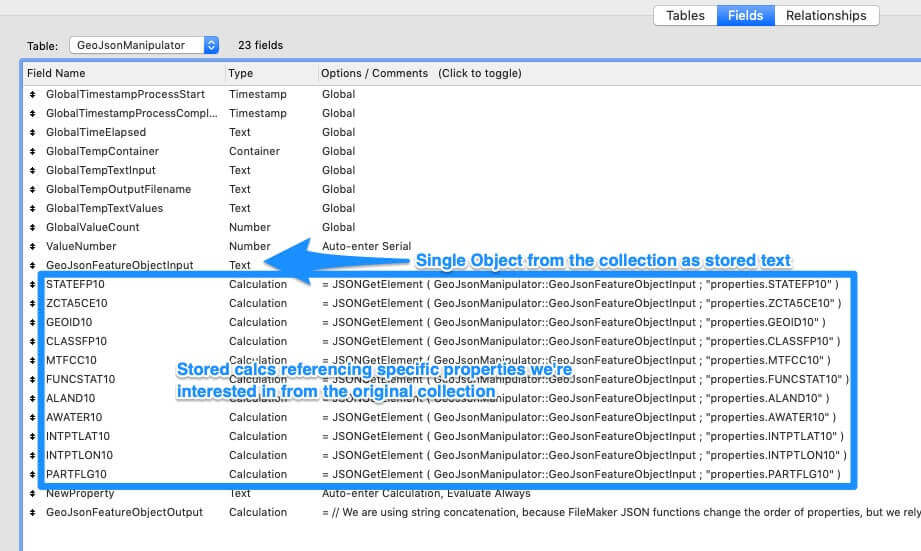
The GeoJsonFeatureObjectInput is a stored text field. In this case, we have a handful of stored calculations which reference it using the native JSONGetElement to extract our identifying properties into our table.
Then we have our NewProperty field, into which we can add our custom metadata object.
Finally, we have our GeoJsonFeatureObjectOutput field, also a stored calculation. We do not use the native JSONSetElement function to manipulate our input object — remember, we rely on the specific white space and order of the input. If we used native JSON functions to rewrite the object, we’d scramble these. We should, therefore, use a simple concatenation technique in the Output field, which preserves the formatting.
Extracting the JSON Collection from the Source File
Lastly, we need to get the JSON collection out of the source file and into FileMaker. In the demo files, we use the native file manipulation features, but you can achieve the same thing with a file plugin.
The file manipulation has been encapsulated into a sub-script called _Ingest File. We’ve annotated the script if you’re interested in the implementation. This process converts the input JSON collection into a Value List, with each value comprised of a single GeoJSON Feature Object.
Splitting Processed Feature Objects Into Records
We can now split up the processed Feature objects into records. Here we can compare two alternatives techniques.
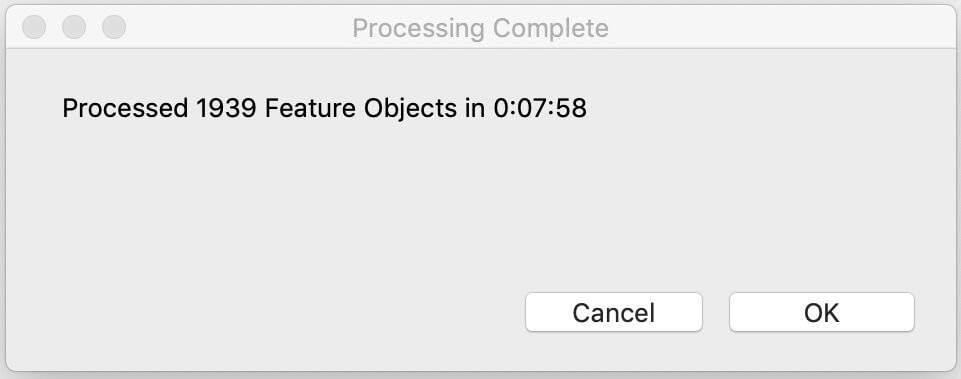
Technique 1: Looping Over the Value List
At first, you may want to loop over the value list. Loops are often fast, and this seems like a direct way to handle it. While this did get the job done, we found it was still pretty time-consuming. On a decent computer using local files, Texas took eight minutes to process. FileMaker was no longer freezing up, but we wanted to process all fifty states’ zip codes on a fairly regular basis. This was less than ideal.
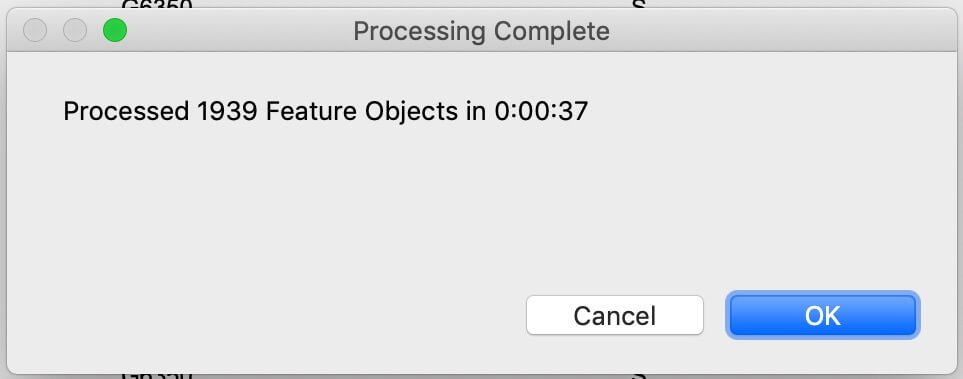
Technique 2: Importing Prepared Values
We then realized we could probably import the prepared values from a file as if it was a one-column CSV without much extra effort. We should only need to export the value list as a file and treat it as a one-column import. We just had to add a header row and alter the default line break that FileMaker uses. If you’re following along with the demo file, you’ll see these prep steps in the _Ingest File script. The surprising finding here was that our processing time was ten times faster.
Next Steps for Your FileMaker Solution
We hope you have a better understanding of how to handle a JSON collection in your FileMaker solution quickly and efficiently.
If you have any questions about this process or have questions about another challenge in FileMaker, please feel free to contact our team.