This is part of an ongoing series of AWS related posts. Here are other posts in this series:
- FileMaker Server on Amazon Web Services Quick Start Guide
- FileMaker Hosting Info and More Fun with Amazon Web Services
Looking for FileMaker hosting services? Learn more about Soliant.cloud, our offering that combines our team’s FileMaker and AWS expertise.
We all know backups are a good thing. There has been plenty written on how and why you should have a good backup strategy in place, especially for FileMaker Server. So now you have done all that, make backups frequently and go to sleep secure in the knowledge that you are covered.

Now let us take things to the next level with secure offsite, cloud hosted backups that are redundant and replicated to other regions. AWS S3 is a great option for low-cost storage, and is extremely scalable and secure. Having copies of the files in S3 ensures that if something happened to your FileMaker Server, or even the EC2 instance you are running on, you could get those files back up on a new server as part of your disaster recovery plan.
The steps involved include:
- Install the AWS Command Line Interface tools.
- Configure a script and schedule if from FileMaker Server.
- Configure your S3 bucket options.
What is S3?
S3 stands for Simple Storage Service, and is part of Amazon Web Services offerings. If you haven’t seen our quick start guide for hosting FileMaker Server on AWS, you can view it here.
The instructions below are suitable not only for EC2 hosted virtual server, but also any FileMaker server wherever it may be running.
AWS CLI
Once you install the command line interface (CLI) for AWS, it is relatively easy to get files from your FileMaker Server machine into a S3 bucket. The CLI is available for both Windows and Mac OS, but our example here will focus on the Windows deployment, in part because AWS offers Windows servers. The steps for Mac OS server hosted on premises would be similar, but instead of a batch script, you would write a shell script.
Set up an IAM (Identity and Access Management) account, and create an access key that we will use. Log into the AWS Management Console and go to the IAM section to manage access. For more on that, you can view the reference linked here.
Note: The access info needed, including the Access Key ID and Secret Access Key. You will use the access key in the batch file we show in the next step.
Create the batch file
set AWS_ACCESS_KEY_ID=YOUR_ACCESS_KEY_ID
set AWS_SECRET_ACCESS_KEY=YOUR_SECRET_ACCESS_KEY
set AWS_DEFAULT_REGION=(for example, us-west-2)
aws s3 sync "C:Program FilesFileMakerFileMaker ServerDataBackups" s3://bucket-name ‐‐deleteThe “‐‐delete” flag is optional and tells the sync command to remove any folders of files from the bucket that do not currently exist in the local file system. You can optionally leave that flag off and manage what files are kept and how long to keep them from S3 as well, as we will see below.
Note: The path in the example is the default path, if you have installed your FileMaker Server in another location or have set a different backup path you will need to adjust the batch file to reflect your actual backup path.
Schedule to run from FileMaker Server
Once you have edited the above sample with your information, you will save it to the Scripts folder in your FileMaker Server installation. Only scripts saved here will be available to schedule using the built in scheduler included with FileMaker Server.
Note: FileMaker server runs as a daemon on the server as the user fmserver. That is why the access key information needs to be in the script instead of configured from the command line
Schedule the batch file to run at interval, after your normal backup routine has finished running. FileMaker backups should be allowed to complete before moving to S3, so it is a good idea to schedule these accordingly.
Note: Another thing you could do here, to ensure that the backup occurs before transfer to S3, is to include the backup command in the batch script. FileMaker Server has its own command line interface to do this
S3 Bucket Options
Here is where things get interesting. There are several options available that you can enable with your S3 buckets. Here are several that I think are applicable and you may want to review when considering your backup strategy.
What is a Bucket?
Buckets are the containers for objects. You can have one or more buckets. For each bucket, you can control access to it (who can create, delete, and list objects in the bucket), view access logs for it and its objects, and choose the geographical region where Amazon S3 will store the bucket and its contents.
Enable versioning
Versioning allows you to automatically have a copy of a file each time it changes, even if the files are deleted. Enabling versioning also allows for other options like Cross Region Replication. If you are using the delete option in your script to save to S3 with versioning enabled, even though your backups may have been deleted on the server, you can have a redundant copy of them in your S3 bucket.
Set up Lifecycle policies
Setting up a policy on an S3 bucket is easy and straightforward. S3 includes a couple different tiers for longer term and lower cost storage, including Glacier. These are meant for more infrequent access and longer term storage for files that may not be needed to access on demand.
A sample policy you might set up would be one that moves the files to infrequent access after a period of 30 days, then to Glacier after 60 days, and finally delete from the bucket after a year.
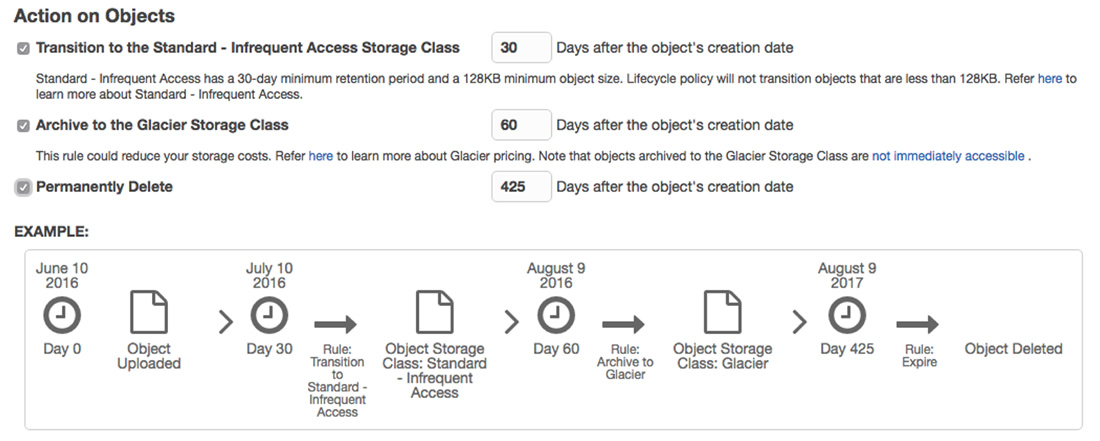
Keep in mind that accessing files stored in Glacier is not on demand. To keep costs low, Amazon Glacier is optimized for infrequently accessed data where a retrieval time of several hours is suitable.
Cross Region Replication
For maximum peace of mind, you have the option of replicating your S3 bucket to another region. That way, if the west coast has a major cataclysmic event and all the data centers in that region are destroyed or taken offline, you can still access a copy of your files from an east coast data center.
Pricing
Costs for S3 storage are low and affordable. As with most AWS options, it depends on your implementation, but just for reference, they currently start out at around 3 cents per month for the first TeraByte you use, and it goes down to .7 cents (that is POINT SEVEN cents) per month for Glacier storage.
You can see more details on the S3 pricing page here:
There are also some costs for the bandwidth for getting content to and from S3. However, if you are using an EC2 instance to host your FileMaker Server, that bandwidth is free to use since it is all on the AWS side.
For most deployments, I think the cost would be quite justifiable for the redundancy and peace of mind this offers.
Special Thanks to Wim Decorte for providing feedback on this post as well.
Pingback: Backups in the Cloud with AWS – FileMaker Source
Thanks for article. Very useful. I have tried to get this working but my batch file just runs and nothing appears in my bucket. I have gone through the CLI for AWS configuration and setup my bucket permissions to allow any authenticated AWS user to upload/Delete. Is there something els that could be stopping the upload. I have tried to view the command line result but not sure where to view the logs that may indicate a problem.
Hi Kevin,
You might try to run that last line manually in the command prompt. To do this, you may need to configure the AWS CLI with your info, instead of specifying it in the batch file. You should be able to troubleshoot from there, and tell if the issue is misspelled bucket, account, etc.
Terrific option for FMS backups in the cloud. Your clear instructions made setting this up a breeze. Thanks a lot!
Pingback: Devcon Un-Conference, AWS S3, Google and FB Thumbs Up - FileMakerProGurus
How can i do the batch for a Mac Mini ?
Thanks.
Hi Joan,
You can install the AWS CLI for Mac OS to do this. You wouldn’t use a batch file, but a shell script or applescript and you can do the same thing. Does that help?
Mike
Then, the second question is ……… any idea to do that ? (i come from win world, sorry)
The installer is available here: https://aws.amazon.com/cli
The scripting on OS X will look pretty much like the examples you can find for linux, running bash shell. I suspect the biggest hurdle you may find is running the script under the fmserver user, so you may need to switch to that user to run the config to add the correct keys and pass to that, unless you pass them as part of your script. I haven’t set this up on OS X, but it is supported in AWS CLI.
I have had some success with running shell scripts on OS X and FM Server as an applescript, or use an applescript to launch a shell script to overcome some permissions errors I run into some times, but not sure if this is needed here. I’ll report back if I get the chance to test.
Mike
Thanks Mike, itΓÇÖs very helpful.
One challenge it come across is when I put the script to Filemaker schedular to run. It returned an error said ΓÇ£aborted by userΓÇ¥. Any clue for this? ItΓÇÖs in Windows environment.
Hi Oliver,
You can test the script by running it manually in the command line. If it runs OK, then you likely need to restart. If the AWS CLI is installed after FM server is already running, you will need to restart in order for it to see the CLI.
Mike
Can you please give me an idea what the batch file code would be to download an ENTIRE bucket to a local, external HD? ΓÇô I am having trouble finding such code. – Jonn
You could always install the AWS CLI on that machine, then use the copy command (cp) to download it from a specified bucket. That would look like:
aws s3 cp s3://mybucket . –recursive
Just be aware of data throughput rates would apply, and could add up if the file sizes were large.
Mike
Mike thanks !
Everything works fine. One thing I ran in to was when I ran the script manually there was no problem but when running in a schedule I got errors (without a account in the fms schudule: “aborted by user” with a server account “could not be found or is invalid” )
The solution for me was to add “.\” before the account name (example: .\Administrator)
Local Machine account Example -> “.\”
Local Machine account Exmaple -> “\
Domain Account Example -> “\
Do you have a suggestion how to setup S3 backups with a lot of Documents?. I have a system where every daily backup is 60GB. It’s a cloud based server so backing up to a local drive is no option.
Thanks for the effort.
If you use “sync” as shown, it will only copy files that are new or that have changed. For example, if you have externally stored container data, that can add up, but will only need to sync the differences. You might also consider scheduling the script to run with OS scheduling to avoid running over the FMS time limit for scripts to run. If this is an AWS hosted server, then all data transfer will happen on the AWS side of the network and should run faster.
Hi, I am having trouble with Mac fms16. When I run as system script, it says that script missing or is invalid. When I try the aws code in terminal it works though..
There are some additional requirements for running shell scripts with FM Server on OS X, if you look in the help pages for your server. As an alternative, what I have gotten working on OS X is to call your script with applescript instead, having the shell script called in the applescript, and call that script from the FMS schedule. That seems to avoid the extra setup for shell scripts on OS X.
This works wonderfully but it’s choking on the –delete flag, any ideas? I will of course also consult the AWS CLI Docs 😉
Ok, this problem appears to have gone away, perhaps it’s related to some sort of high ASCII character being left in the string I pasted into the prompt after being copied and pasted between my mac and the remote windows machine I am using. The AWS CLI is a little intimidating and it was a challenge to install for me, apparently it’s there by default on EC2 machines, but when this thing works it works exceedingly well. very reliable and simple.Thanks!
Sure would be nice if Soliant would provide a working solution template/example for users running FMPS on a Mac box. Believe it or not, many seasoned FMP developers aren’t CLI whizzes, so having a working template would be extremely useful.
Just one example, a very basic thing: what do you put in for a MacOS file path in the fourth line of the example above? Does it start with the “Volumes/Macintosh HD/Library… ” etc or from the HD root…”/Library” etc. Slash at the end?
These are the niggling one-thousand paper cuts that make this otherwise good idea a multi-hour task instead of the 5 minute one it should be.
Mike,
In the example for Windows you use:
aws s3 sync “C:Program FilesFileMakerFileMaker ServerDataBackups” s3://bucket-name ‐‐delete
I’m having a problem with the Mac backup directory noon. What would it be the correct syntax for this directory?
“Macintosh HD/Library/FileMaker\ Server/Data/Backups/Noon”
Thank you
John
I have not tested on Mac OS, but that path does not look correct. If you open terminal app on Mac, you can drag and drop the folder you want to view the path for and it will show you the correct posix path. Does that help?
I was having trouble running my batch file as the scheduled script. I was getting an error saying the user aborted script.
I found a post that mentioned making sure the encoding is UTF-8. My batch file was set to Unicode and when I changed it UTF-8 it worked each time.
I’ve used this script for years on many servers. Thanks for that!
Should this also work on Linux/Ubuntu? I’ve been searching for an example but couldn’t find it so far.
Thanks!
You can install the AWS CLI on linux, yes.
I know this article is a few years old now but we are trialling the script to backup to AWS S3 and it works really well and as described above it is a very good way of having essential backups.
However, we have found that it dominates the resources in terms of bandwidth and cpu usage. We are running a M5.xlarge which is 4 vCPUs and 16gb memory and up to 10gb bandwidth. But when the backup process script runs it stretches all areas of the server except RAM, that is comfortable. Is there a way to load balance it? I appreciate that may take a bit longer to do, currently it takes about 35 minutes to complete the backup.
Thanks, any suggestions welcome.
Are there a lot of container data objects? The number of objects can greatly impact how long it takes to complete. If so, you might look at how container data is stored and possibly move to a separate folder…see the option in the FM admin console…and then sync those separately since a sync will be faster than copying all those objects.
You might also consider using snapshots instead of copying files to S3. If you do that, you need to pause all files before taking a snapshot, then resuming them. This is how we do it with our managed hosting service.